MACで、自分の声を他人の声に変える、RVCリアルタイム ボイスチェンジャーを試してみした。使い方を解説します。
VC Clienを使えば、リアルタイムで変換もできます。今回は録音した音声を他の人の声に変える、音程を
変更して違う声に変える方法を解説していきます。 録音した自分の声を他の人に声に変えたり リアルタイムで自分の声を 他の人の声に変えることができます。
だだっこぱんださんが開発されたRVC-WEBUI
今回は、だだっこぱんだ さんが開発した、RVC-WEBUIを使ってみます。
オリジナル版のRVC-WebUIは、contentvecという事前学習モデルを使い、256次元のphone embeddingsを用いて音声変換を行います。声の特徴を変えるにはキー調整を行います。
だだっこぱんださん版のRVC-WebUIは、元の版を再構築し、contentvecに加えてhubert-base-japaneseやdistilhubertなどの事前学習モデルが使用できます。768次元のphone embeddingsにも対応し、音声の品質と精度が向上します。更に、だだっこぱんださん版では、学習時にAugmetinやk-means法によるデータ圧縮の機能も追加されています。
rugmet機能をを使うと、さらに精度の高い学習学習ファイルが作れるようでです。ただ、指定するファイルの作り方、設定の仕方が不明で、これはおいおい解説していきます。今回は基本的な使い方を。Augmet機能を使わなくても、十分他の人の声に変えたり、自分の声を変えたりはできます
それでは、まずは事前準備から。
事前準備(pythonとFFmpegをインストールしよう)
まずは 事前準備として Python とFFmpeg をインストールしておく必要があります
pythonをインストール(MACはほぼpythonが既にインストールされています。むしろ、最新のpythonではエラーになってしまった…)
pythonをインストール
標準のMACでは Python がインストールされています。 ただし マックのバージョンによっては Python のバージョンが古い可能性がありま
ターミナルでいかのコードでpythonのバージョンを確認しましょう。
lauchpadで”ターミナル”と検索すると、ターミナルを見つけることができます。

ターミナルをクリックして立ち上げます。

MACには元々ythonがインストールされている
MACはほぼ、は元々pythonがインストールされています。RVCを動かすのに最新バージョンは必要ないかも、、と言うのも、pythonの最新バージョンで、エラーになり、MACのプリインストールされいてるpythonではエラーになりませんでした!
|
1 |
<p>python --version</p> |

zsh: command not found: pythonとなったら、python3と打ってみてください。これでpythonのバージョンが出てこれば動かせます。これでエラーにならなければ、ひとまずMACにプリインストールされたpyhonで、RVC〜WEBUIは動かせます。
|
1 |
python3 |
念の為、pythonのインストール方法をお伝えします。
ターミナルで以下のコマンドを打ちます。Homebrewと、pyenvを使ってpythonをインストールする方法です。
Homebrewをインストール
|
1 |
<p>/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)"</p> |
Xcode Command Line Toolsをインストールする
|
1 |
<p><p>xcode-select --install</p></p> |
pyenvのインストール
|
1 |
<p>brew install pyenv</p> |
pyenvの設定
pyenv
|
1 |
echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.zshrc |
|
1 |
<p>echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.zshrc</p> |
|
1 |
<p>echo 'eval "$(pyenv init -)"' >> ~/.zshrc</p> |
インストールできるpythonを確認
以下のコマンドを打って、インストールできるpythonのバージョンを確認します。
|
1 |
<p>pyenv install --list</p> |
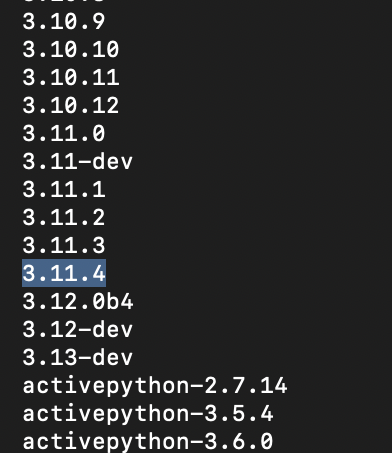
3.11.4でエラーになったので、もう少し古いバージョンで。
|
1 |
<p>pyenv install 3.10.9</p> |
以下のコマンドでインストールされているかを確認することができます。
|
1 |
<p>pyenv versions</p> |
インストールしたpythonを使えるようにする
このままだと、MACのデフォルトのpythonのバージョンが動いてしまいます。
以下のコマンドで、インストールしたpythonを利用できるようにします。
|
1 |
<p>pyenv global 3.10.9</p> |
FFmpegをインストールしておく
今回は、homebrewがインストール済みなので、homebrewを使ったFFmpegのインストール方法をお伝えします。
以下のコマンドを打ちます
|
1 |
<p>brew install ffmpeg</p> |
FFmpeg情報があることは以下のコマンドで確認できます。
これで事前準備は完了です。
|
1 |
<p>ffmpeg -version</p> |
RVCでは 自分の声を 人の声に変換したり 、自分の声を変えて他人の声 のようにしたり(音程を変える)ことができます。以下、3つの手順でご紹介します
1.RVC-webuiをインストール
- RVC-webuiをMACにインストール(ダウンロード)
- ターミナルでwebui.shを実行。
- ブラウザでhttp://127.0.0.1:7860にアクセスして、webUI開く
2.RVC学習モデルを作成する
*BOOTHなどで変換したい学習済みモデルがあればそれを利用してもOK
- 音声を収録(30分分ぐらい?)細切れに。
- RVC-webuiのTrainタブで学習させる。
3.録音した音声をボイスチェンジする。
- 学習済みのモデルを./models/checkpointsに
- webUIのInferenceタブで、モデルと音声ファイルを選択して、Inferボタンを実行
- 録音した音声を変換する方法
- リアルタイムで音声変換する方
1.RVC-webuiをMACにインストール(ダウンロード)

gitリポジトリからコードをクローンする手順は以下のようになります。
ターミナルを開く。
Lanuchpad→ターミナルで検索すると出てきます。

ターミナルのアイコンをクリックして立ち上げます。
ターミナルを開きます。
コードを保存したいディレクトリに移動します。例えば、デスクトップに保存したい場合は、cd ~/Desktopと入力します。
|
1 |
<p>cd ~/Desktop</p> |
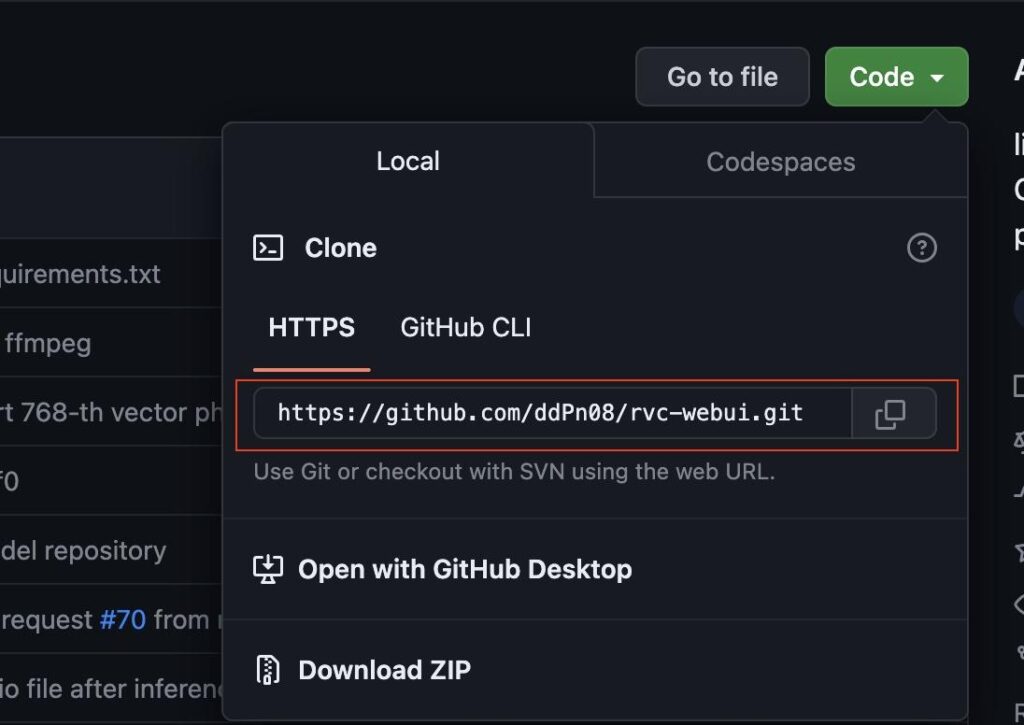
https://github.com/ddPn08/rvc-webui にアクセスし、緑色のCodeボタンをクリックします。すると、Cloneというメニューが表示されます。
ddPn08/rvc-webuiのGITHUBページ
https://github.com/ddPn08/rvc-webui
Cloneの中から、HTTPSを選択し、URLをコピーします。URLはhttps://github.com/ddPn08/rvc-webui.gitとなります。
ターミナルでwebui.shを実行する
./webui.sh を実行します。または、webui.shをクリックして実行します。
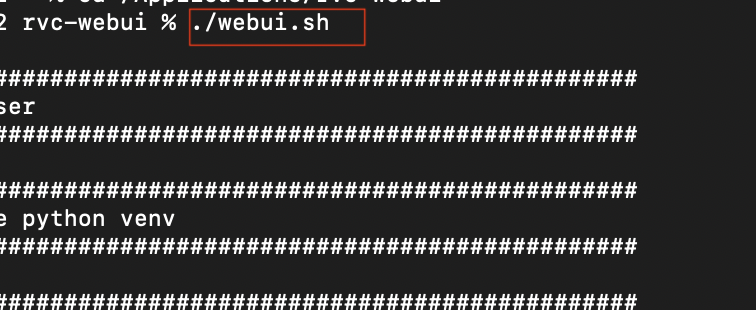
ターミナルに戻り、git clone https://github.com/ddPn08/rvc-webui.gitと入力して実行します。すると、rvc-webuiというフォルダが指定先に保存されます
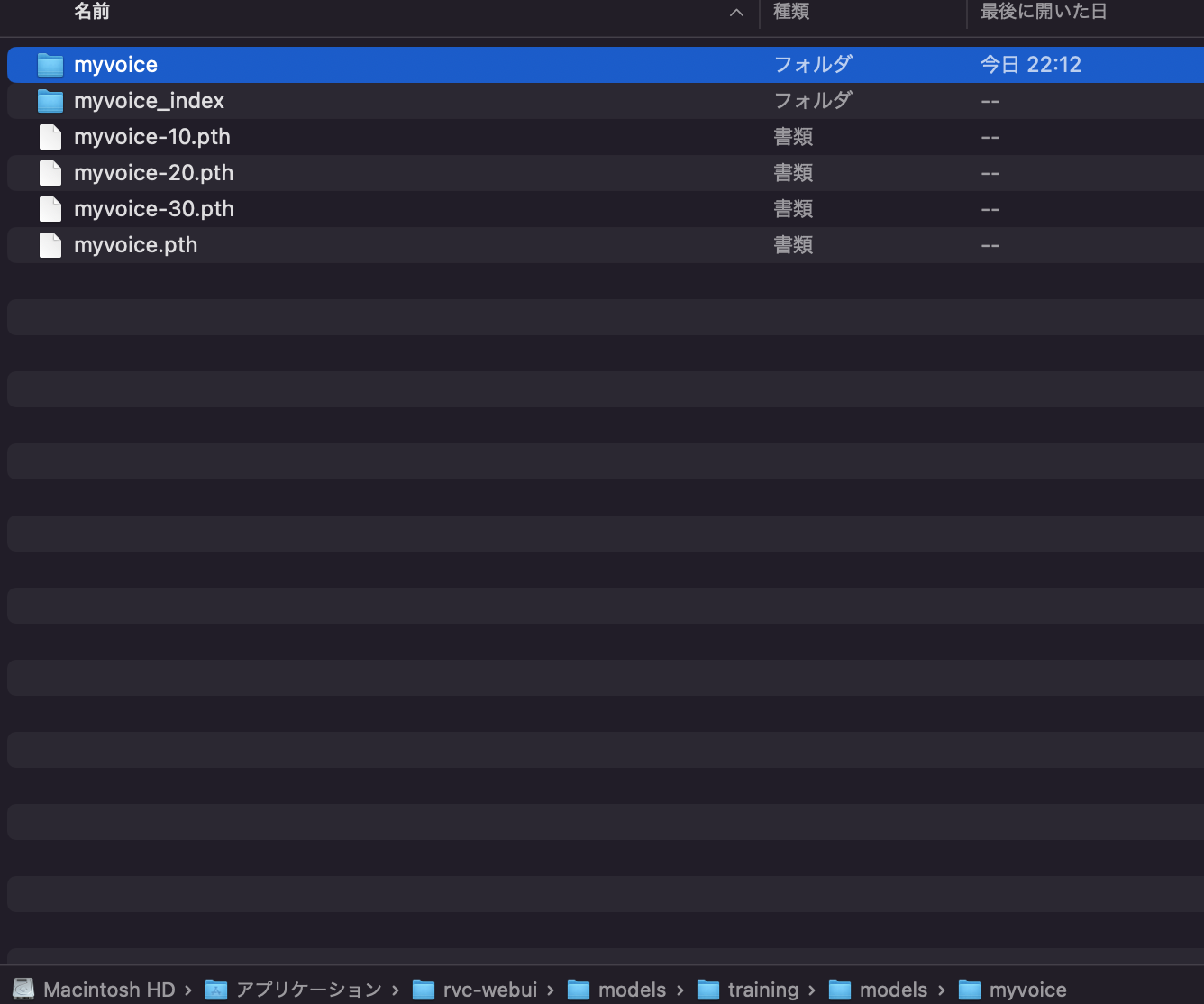
rvc-webuiフォルダの中身です。

ターミナルの画面には、http://127.0.0.1:7860というURLが表示されています。以下のURLをブラウザで開くと、rvc-webuiの画面が立ち上がります。
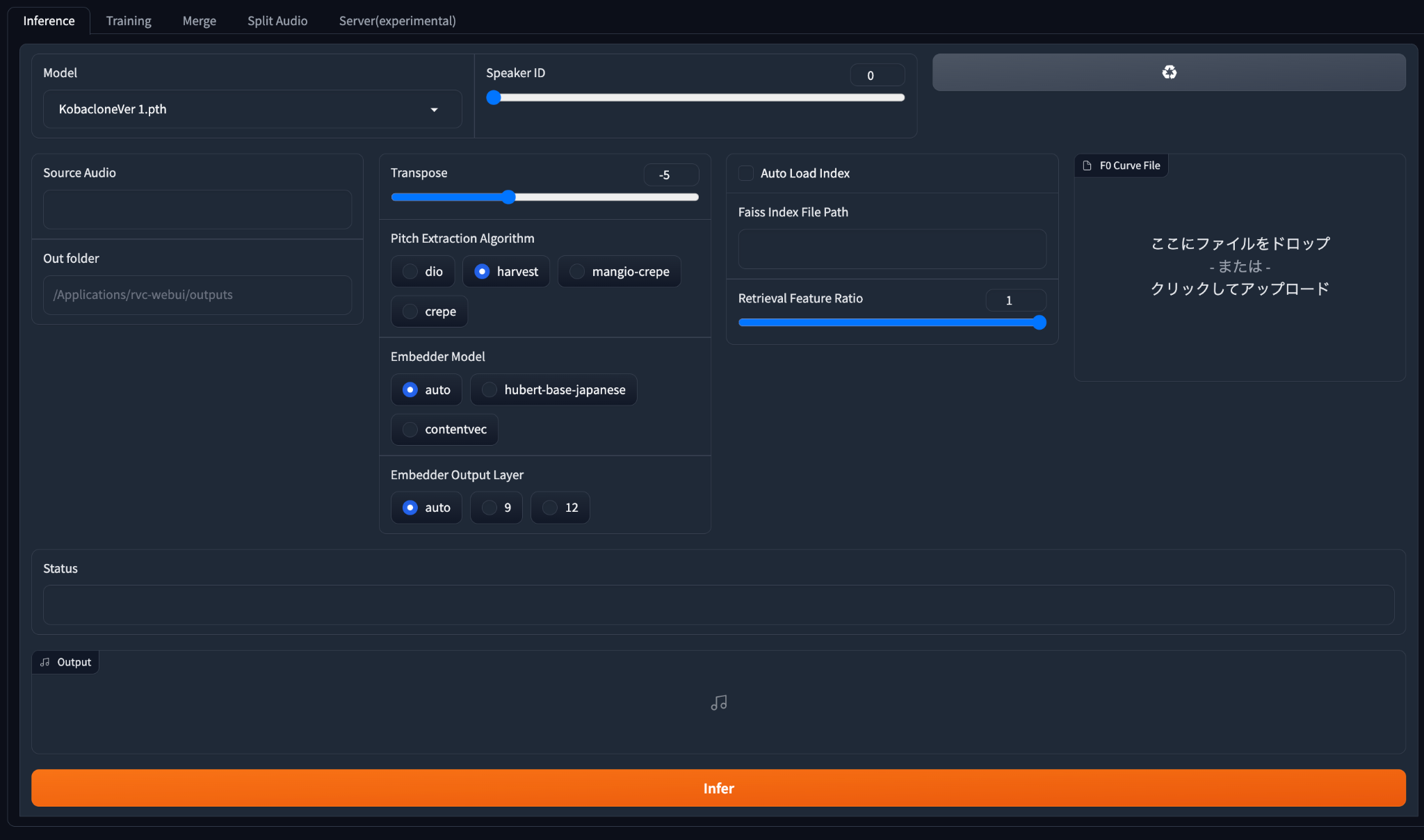
RVC -WEBUO4つのタブ。(Inference Training Merge Split Audio Server(experimental)
タブは、4つあります。ボイスチェンジに使うのは、inferenceとtrainingのみ。

Inference(音声生成)
の音声を生成をするタブです。入力音声と目標音声を選択し、音色や音高などのパラメータを調整し他の地、音声を生成します。
Training(音声学習)
このタブでは、音声変換のモデルを訓練するタブ。訓練用のデータセット(音声)を準備し、モデルの設定や学習率などのハイパーパラメータを指定して、モデルの学習を開始できます。
Merge(音声結合)
このタブでは、複数の音声ファイルを一つに結合することができます。結合したい音声ファイルを選択し、出力ファイル名やサンプリングレートなどのオプションを指定して、音声ファイルをマージできます。
Split Audio(音声分割)
このタブでは、一つの音声ファイルを複数に分割することができます。分割したい音声ファイルを選択し、分割方法や出力フォルダなどのオプションを指定して、音声ファイルをスプリットできます。
Server(experimental)
このタブでは、RVC-WebUIをサーバーとして起動することができます。サーバーのポート番号やパスワードなどの設定を行って、他のデバイスからRVC-WebUIにアクセスできるようにできます。
2.RVC学習モデルを作成する

trainタブでRVC学習モデルを作成します。
先に書いた通りAugment機能は、 使い方が不明なので今回は省きます
学習させる音声ファイルを作る
これは他人の声に変えたい場合は、他人、自分の声を元に作りたい場合は自分の声でも。
販売されているRVC学習済みデータもあります。
BOOTH(RVC学習済みデータ)
https://booth.pm/ja/items/4693675
録音する際におすすめのマイク
ちなみに、録音には、単一指向性マイクがおすすめです。
私は、HyperX SoloCastを使っています。HyperX の上位版でHyperX QuadCastもあり、高機能なのですが、使いこなすのが大変です。HyperX SoloCastが価格も安くてエントリーモデルでおすすめ。
内蔵マイクでもいいのですが、しっかり声を拾ってくれるので、こちらの方が楽だし、音質もいいです。 Amazonが安いです。
→HyperX SoloCast amazon 7980円

MACの内部マイクより、十分音は綺麗!あと、声を拾ってくれて雑音を拾いにくいですし、声を張り上げなくても録音できるので楽です。
Quick time playerで音声を録音
今回は、2、3分程度の音声を12個作りました。WAVファイルに変換する必要があります。
1本10分以上だとエラーになり、うまくいかない可能性あり。
アプリケーションからQuick time playerを立ち上げ→オーディオをクリック。
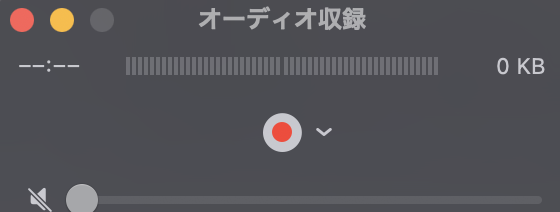
赤のマルをクリックすると、録音開始。
▪️をクリックで、録音終了。
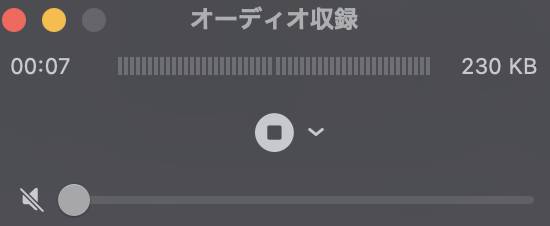
ommand+Sで保存。
aifcファイルで保存されます。
Apple musicを使ってファイル形式をWAV に変換
RVCで学習できる
ミュージック→設定→ファイルタブ→読み込み設定
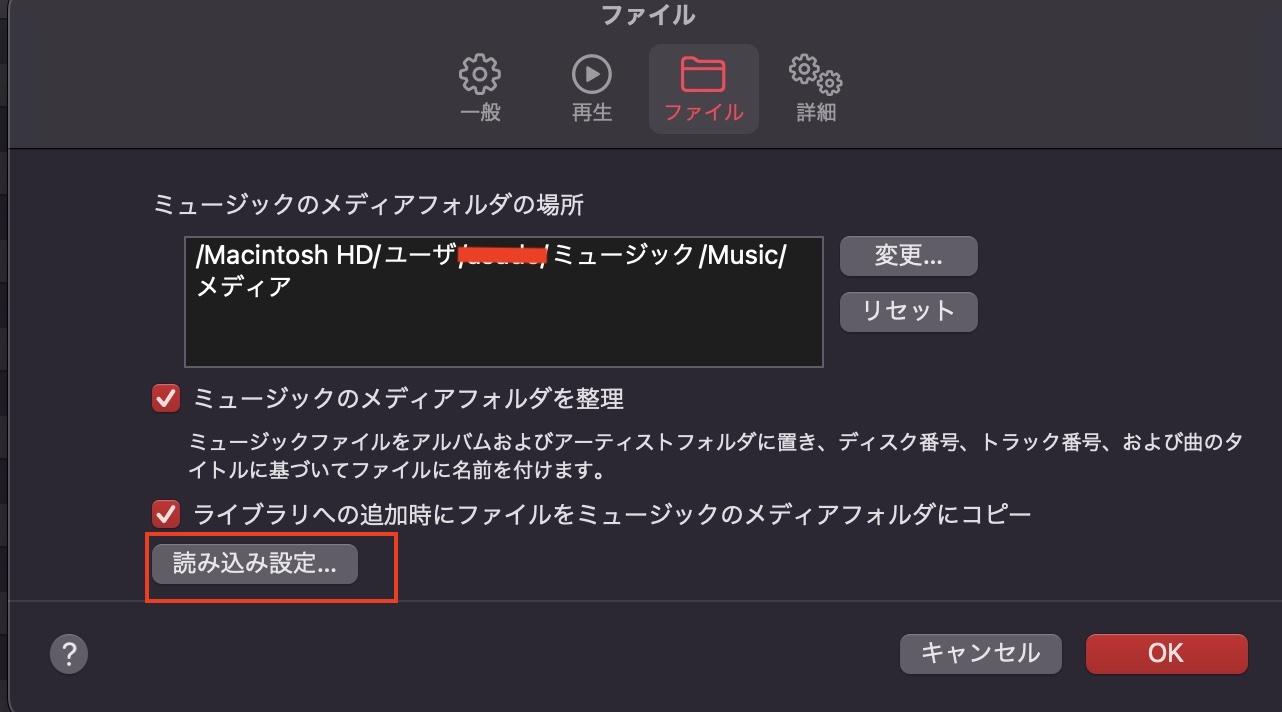
WAVエンコーダをクリック。
音声ファイルからWAVを作成
ファイル→変換→WAVバージョンを作成
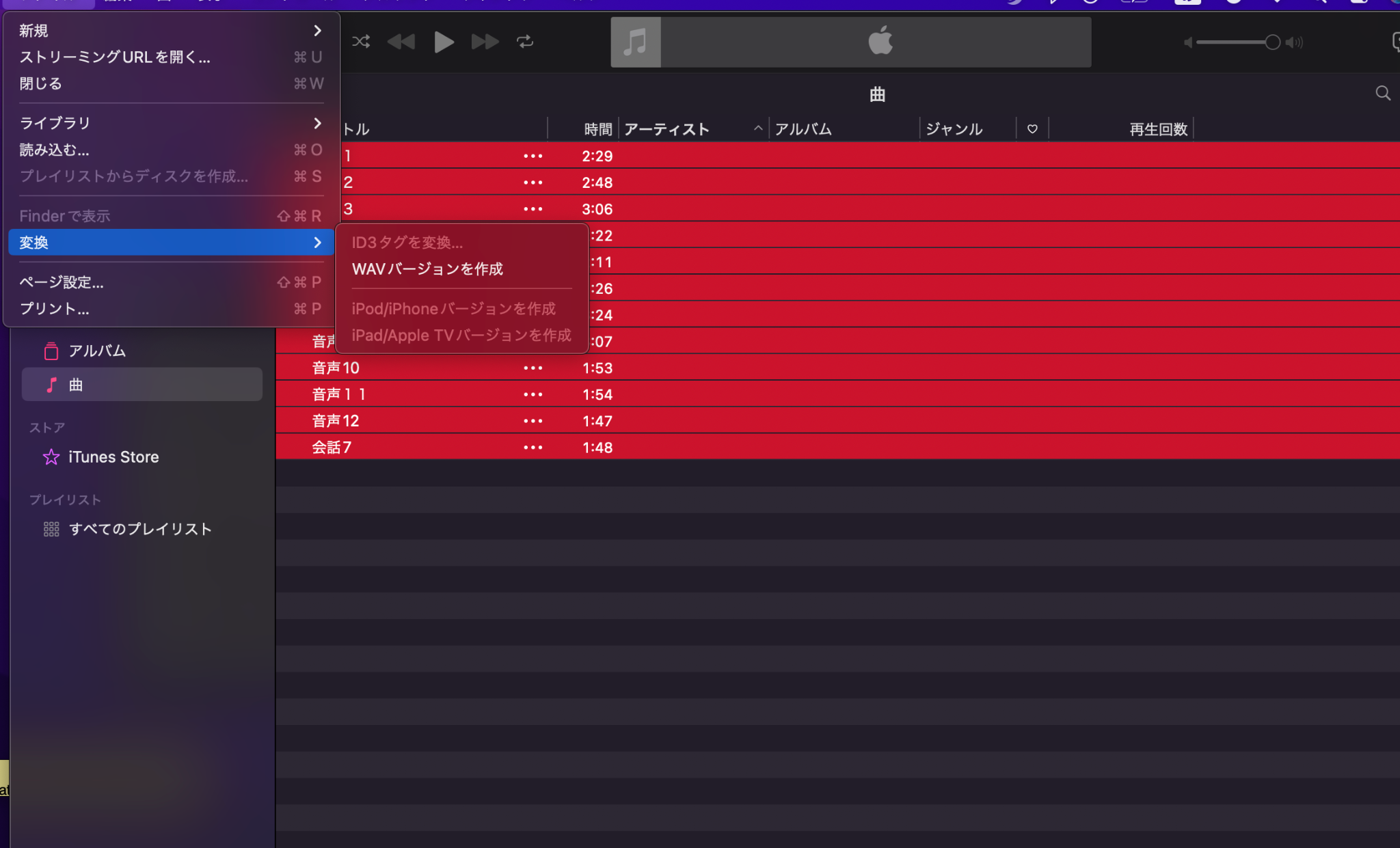
ユーザー→ミュージック→メディア→UnnownArtist→Annownアルバムの中に、生成された
WAVファイルが入っています。
Trainingタブで音声を学習させよう
なぜ音声のトレーニングが必要?
モデルが学習することは、音声データから音声の特徴や内容や関係などを覚えることです。この特徴を保存したpthファイルを利用して、自分の声を保存されたpthファイルの特徴に置き換える感じかなと。
Trainingタブで、学習済みデータを作成する
trainタブを開き、作成した音声フォルダ先を指定して学習させます。
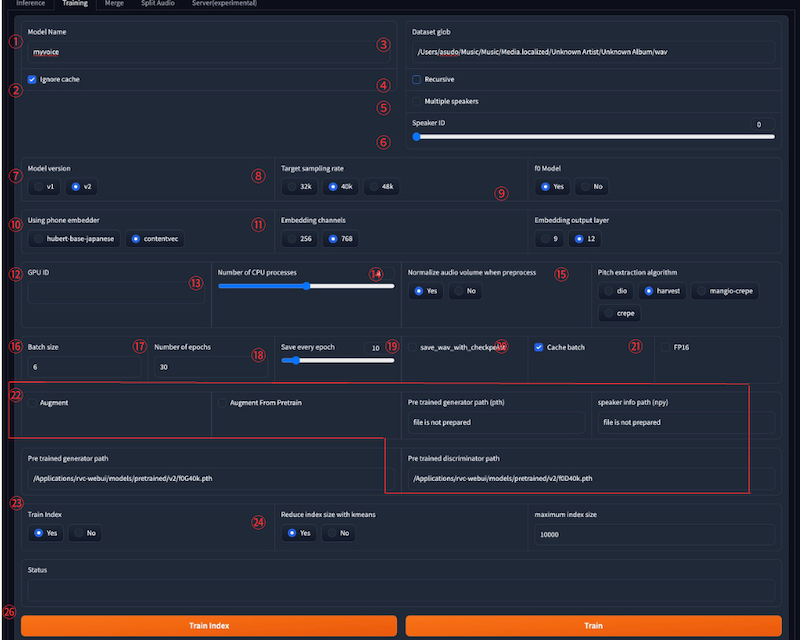
パソコンのスペックなど状況によって変わるので、設定は色々試して見るのが良いかなと思います。
①RVC学習済みデータは、販売されているものを使っても良いです。(その方が楽かも)
Model Name: 学習済みファイルの名前を入力します。
②Ignore cache: 以前の学習結果を無視して新しく学習する場合はYesにします。
途中から再開する場合はNoにします。
③Dataset glob: 学習に使う音声ファイルのパスを指定します。例えば、「data/**/*.wav」なら、dataフォルダ以下のすべてのwavファイルを使います
指定したいフォルダを選び、optin+command+Cでパスをコピーして貼り付けます。

④Recursive: Dataset globで指定したパスにサブフォルダがある場合に、その中の音声ファイルも使うかどうかを選択します。Yesなら使います
⑤Multiple speakers: 学習に使う音声ファイルが複数の話者のものである場合チェックを入れます。
チェックを入れないなら単一の話者となります。

⑥Speaker ID: inferタブなどで学習済みモデルを使う際に、識別番号を使う場合の保存に使うようです。
明確に説明されているところがなく、ゼロで指定されているようなので、このままゼロのまま進めます。
⑦Model version: 学習するモデルのバージョンを選択します。v1は古いバージョンで、v2は新しいバージョンです。v2の方が精度が高いとされています。
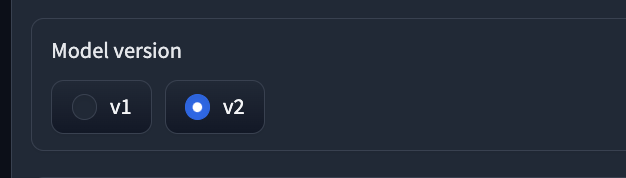
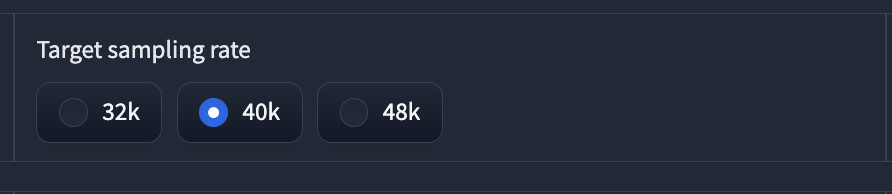
⑧Target sampling rate: 学習する音声ファイルのサンプリングレートを選択します。32k, 40k, 48kの中から選べます。高いほど音質が良くなりますが、学習時間も長くなります。
今回は40Kを選びます。
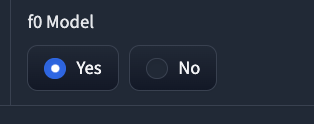
⑨f0 Model: 音声変換時にピッチを変更するかどうかを選択します。Yesなら変更します。Noなら変更しません
ピッチ=音程です。変える可能性が高いのでyesにしておきます。
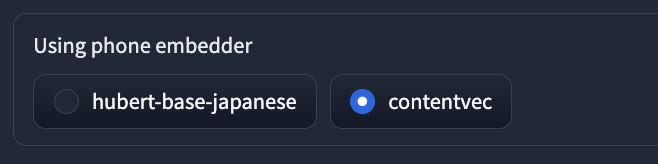
⑩Using phone embedder: 音声変換時に音素レベルでの変換を行うかどうかを選択します。hubert-base-japaneseなら日本語用の事前学習済みモデルを使います。contentvecなら英語用の事前学習済みモデルを使います。
今回は、contentvecを使います。hubert-base-japaneseでも試してみてください。
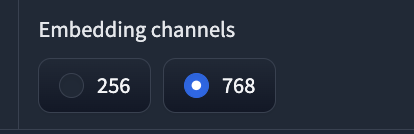
⑪Embedding channels: 音声変換時に使う埋め込みベクトルの次元数を選択します。256, 768の中から選べます。高いほど情報量が多くなりますが、学習時間も長くなります。
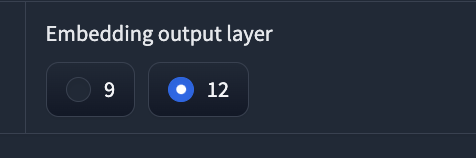
⑫Embedding output layer: 音声変換時に使う埋め込みベクトルの出力層を選択します。9, 12の中から選べます。高いほど情報量が多くなりますが、学習時間も長くなります。
⑫GPU ID: 学習に使うGPUのIDを選択します。GPUが複数ある場合は、空きのあるものを選んでください。
*入力不要
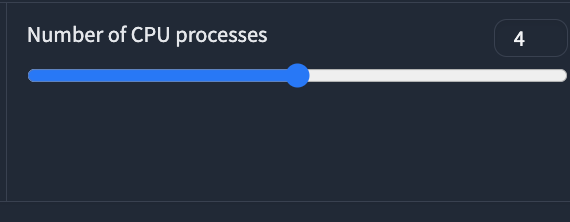
⑬Number of CPU processes: 学習に使うCPUプロセス数を選択します。4以上推奨です。
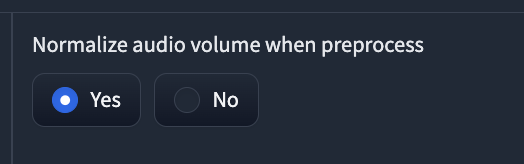
⑭Normalize audio volume when preprocess: 学習前に音声ファイルの音量を正規化するかどうかを選択します。Yesなら正規化します。Noなら正規化しません。
ここは、yesにします。
音声ファイルを学習させるときに、音量の違いのバランスを整えることは、音声変換の品質や効率に影響します。 音量がバラバラだと、学習に時間がかかったり、変換した音声が不自然になったりする可能性があります。音声正規化は、音声ファイルの音量を一定にすることで、学習に適したデータを作ることができます。
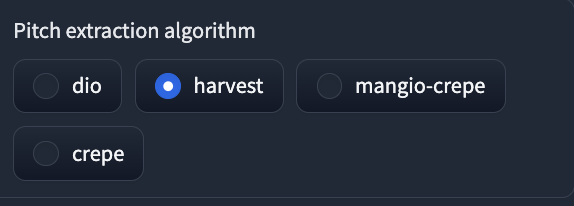
⑮Pitch extraction algorithm: 音声変換時にピッチを抽出するアルゴリズムを選択します。dio, harvest, mangio-crepe, crepeの中から選べます。harvestが最も精度が高いとされています。
harvestにしておきます。
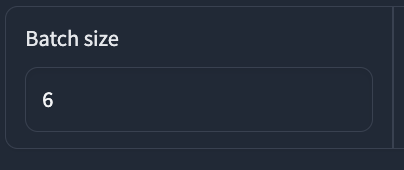
⑯Batch size: 学習時に使うバッチサイズを選択します。4以上推奨です。今回は、6にします。パソコンの容量などでエラーになることがあります。調整が必要。
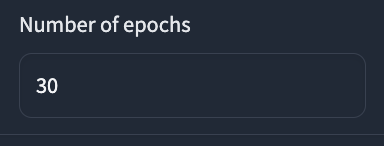
Number of epochs: 学習するエポック数を選択します。30以上推奨です。
⑱Save every epoch: 学習するエポックごとに重みファイルを保存するかどうかを選択します。10以上推奨です。

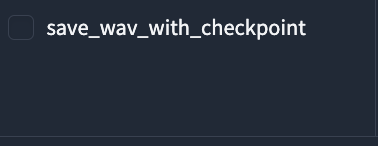
⑲save_wav_with_checkpoint: 学習するエポックごとに音声ファイルを保存するかどうかを選択します。Yesなら保存します。Noなら保存しません。save_wav_with_checkpointとは、RVC-WEBUIの一機能です。この機能を使うと、音声変換の途中経過をwavファイルとして保存することができます。RVC WebUIを実行しているフォルダの中にあるoutputフォルダに保存されます。
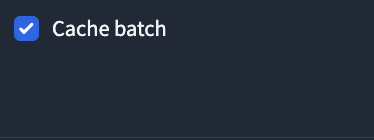
⑳Cache batch: 学習時にキャッシュを使うかどうかを選択します。Yesなら使います。Noなら使いません。
Cache batchは過去に学習させた音源の特徴を利用することができる。(新たな声を学習させる場合はチェック不要)
㉑FP16: 学習時に16ビット浮動小数点数を使うかどうかを選択します。Yesなら使います。Noなら使いません。
16ビット浮動小数点数を使うと、メモリを節約できます。(音質は悪くなります。)
㉒Argument
- Augment/Augment From Pretrain
- Pre trained generator path (pth)/
- peaker info path (npy)
- Pre trained discriminator path
Augment: 学習時にデータ拡張を行うかどうかを選択します。Yesなら行います。Noなら行いません。学習済みデータをどれに指定するのかが難しく..ここを指定ずれば、さらに精度が高い学習済みモデルが作れるようですが、ひとまず未入力にしておきます。
Augment From Pretrain: 学習時に事前学習済みモデルからデータ拡張を行うかどうかを選択します。Yesなら行います。Noなら行いません。
AugmentとAugment From Pretrainにチェックを入れ、Pre trained generator path (pth)と、Pre trained discriminator pathとspeaker info path (npy)を指定
Pre trained generator path (pth): 事前学習済みの生成器の重みファイルのパスを指定します。事前学習済みモデルを使わない場合は「file is not prepared」と入力します。
speaker info path (npy): 事前学習済みの話者情報ファイルのパスを指定します。事前学習済みモデルを使わない場合は「file is not prepared」と入力します。
㉓Train Index
音声ファイルから特徴量を抽出し、検索用のインデックスファイルを作成するかどうか。音声変換の際に、音声の類似度を高速に計算するために必要。
㉔Reduce index size with kmeans
インデックスファイルのサイズを減らすために、k-means法というクラスタリング手法を用いて特徴量を圧縮します。これにより、音声変換の速度が向上する可能性がありますが、音質が低下する
㉕maximum index size
インデックスファイルの作成時間が短くなりますが、音声変換の精度が低下する可能性があります。
10000で試してみます
設定が完了したら、trainindexとtrainボタンを両方おすと、学習を開始します。

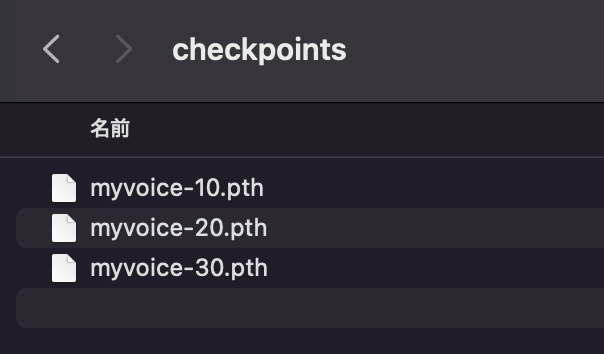
Statusがsuccessになったら完了!
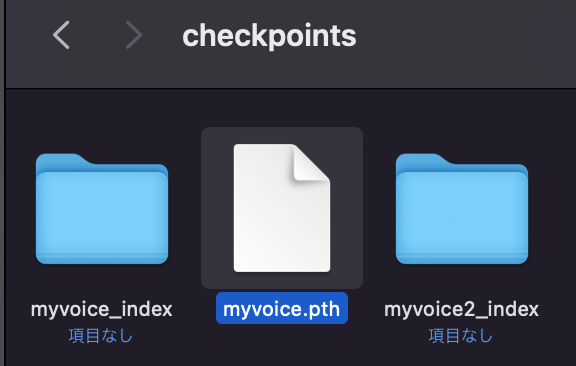
checkpointsの中に、pthファイルができています。
3.録音した音声を変換してみよう

Inference(音声生成)タブ
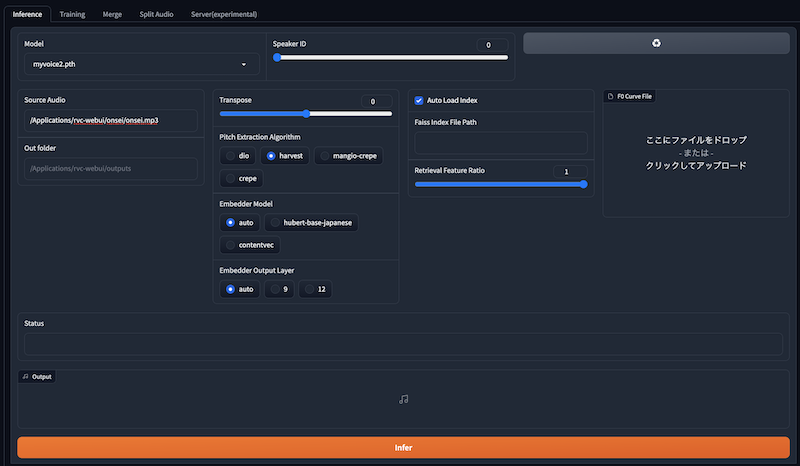
ここで、変換したい別の人の声(学習済みのデータ)を選択します。rvc-webuiのcheckpointというフォルダに、学習済みデータ(.phファイル)を入れておけば、ここで選択できます。
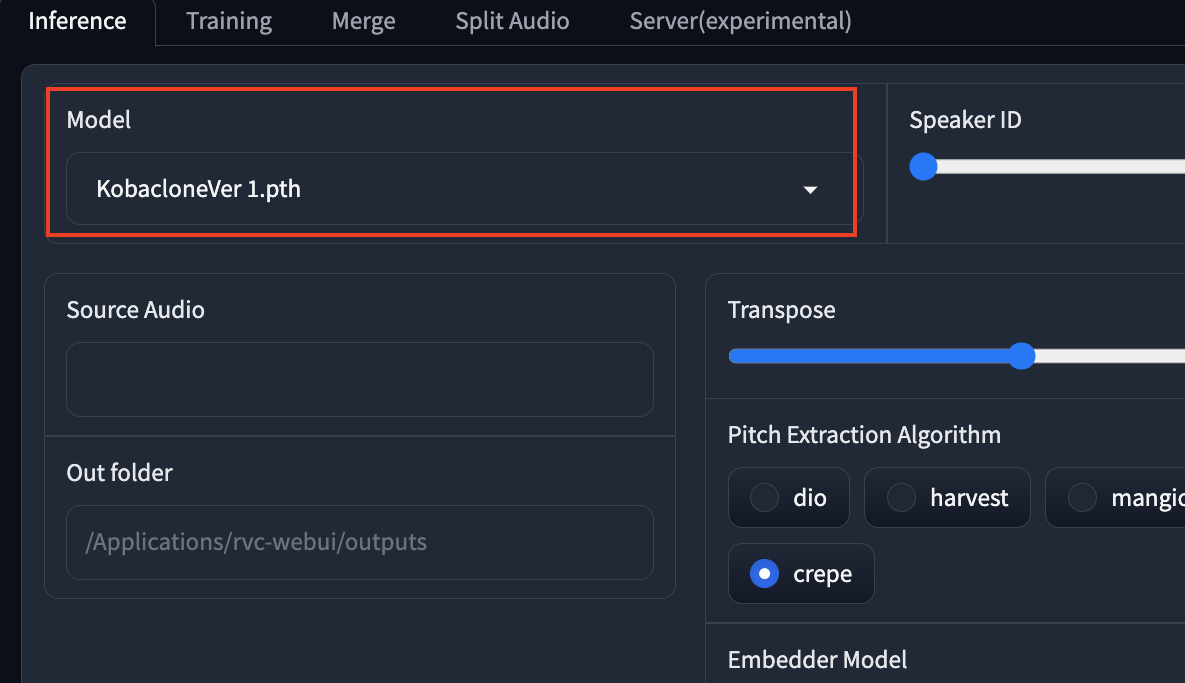
checkpintsというフォルダに入れた.phファイルの学習済みデータを取り込むところです。これが、自分の声などの声を、変換したい音声データになります。
学習済みデータを販売しているサイトもありますよ!
BOOTH RVC学習済みモデル
自分の声など、変換したい声のmp3やWAVデータをSourceAudioで引用します。(rvc-webuiの中にフォルダを作り、その中に音声ファイルを置いてそのパスを指定します。具体的な方法は後ほど)
WAVの方が音質が良い。
WAVとmp3の違いは、音質とファイルサイズに関係しています。WAVは非圧縮の音源で、音質はとても良いですが、ファイルサイズが大きくなります。mp3は圧縮された音源で、ファイルサイズは小さくなりますが、音質は劣化します。人間の耳では聞き取れないとされる音域を削除することで圧縮しているので、細かい音や響きが失われてしまいます。
今回は、mp3で指定してしまいました。
Out folder
生成された音声が出力されてるフォルダです。outputsに保存されます。
SpekerID
こちらは、Trainタブで学習させた学習済みモデルを呼び出せる機能。
(とりあえず0でOK)

Transpose(音程)
Transposeとは、音声変換の際に音程を変えることができる機能です。
例えば、Transpose 3と設定すると、元の音声よりも3半音高くなります。逆に、Transpose -3と設定すると、3半音低くなります。
Transpose の数値が高いと女性の声になり、低いと男性の声になりますね。
pitch Extraction Algorithm
pitch Extraction Algorithmは、音声信号から基本周波数(F0)を推定する方法です。F0は音声の高さや抑揚を表し、声質変換に重要な役割を果たします。RVC-WEBUIでは、4つのアルゴリズムが選択できます。
今回は、音質がいいと言われているharvestを指定します。
pitch Extraction Algorithmの種類
dio(Distributed Inline Filtering with Overlap): 低域通過フィルタを使い調波構造を抽出し、ピークピッキングアルゴリズムでF0を推定します。高速で安定した結果が得られますが、ノイズに弱い欠点があります。
harvest(Harmonic Product Spectrum): 信号の調波積スペクトルを計算し、調波周波数を強調することでF0を推定します。dioよりも高精度な結果が得られますが、計算量が多くなる欠点があります。
mangio-crepe(マンジョクレープ): 深層学習ベースのピッチ検出アルゴリズムであるcrepeに基づいています。音声信号からピッチ特徴を抽出します。品質が高く、改良版のmangio-crepeはさらに高品質ですが、GPUに負荷がかかる欠点があります。
crepe(クレープ): mangio-crepeのオリジナル版で、計算量は少なくなりますが、品質も低下します。
これらのアルゴリズムの中で最適なものは一概には言えません。変換したい音声や使用するモデルによって適したアルゴリズムが異なります。一般的に、品質を重視する場合はmangio-crepeやcrepeを、速度や安定性を重視する場合はdioやharvestを選択。
色々試して見るのが◎
EnbedderModel
音声変換にどの事前学習モデルを使うかを選びます。
autoでOK。日本語に特化した、hubert-base-japaneseを使うと、なぜかうまく出力されませんでした…
なぜだ。
(試してみてもいけれど)
* auto: このオプションでは、音声の言語を自動的に判別し、最適なEmbedder Modelを選択します。英語の音声にはContentVec1、日本語の音声には日本語HuBERT2が使われます。
* hubert-base-japanese: このオプションでは、日本語の音声に特化した事前学習モデルである日本語HuBERT2をEmbedder Modelとして使用します。日本語HuBERTは、約16000時間の日本語の音声で学習したHuBERT-base3。
* contentvec: このオプションでは、英語の音声に特化した事前学習モデルであるContentVec1をEmbedder Modelとして使用します。ContentVecは、約1000時間の英語の音声で学習したHuBERT-base3を元に、話者性を除いた特徴量を得られるように学習しなおしたモデルです。
Embedder Output Layer
autoでOK。
Embedder Output Layerは、Embedderモデルが音声の特徴量を抽出する際の出力層の選択設定です。HuBERT-base1やContentVec2などの事前学習モデルは複数の層から成るニューラルネットワークです。Embedder Output Layerの選択により、音声の特徴量の次元数や品質が変わります。
以下の3つのオプションがあります。
auto: Embedderモデルの種類に応じて、最適な層の出力が自動的に選択されます。例えば、日本語HuBERT1では9層目、ContentVec2では12層目の出力が選ばれます。
9: Embedderモデルの9層目の出力を使用します。音声の特徴量は256次元になります。日本語HuBERT1では、このオプションが推奨されています。
12: Embedderモデルの12層目の出力を使用します。音声の特徴量は768次元になります。ContentVec2では、このオプションが推奨されています。
Embedder Output Layerの違いは、音声変換の品質や速度に影響します。一般的には、autoオプションで最適な層を選択する方が良い結果が得られます。また、12層目の出力を使用すると、計算量が多くなるため、変換速度が遅くなる可能性があります。
Auto Load Index
Auto Load Indexは、変換先の音声を選択する機能。
Retrieval Feature Ratio
ひとまず1にしておきます。
Retrieval Feature Ratioは、0から1までの値で設定できます。0に近いほど、変換元の声に近い話者性になります。1に近いほど、変換先の声に近い話者性になります。つまり、Retrieval Feature Ratioは、変換元と変換先の声の特徴をどれだけ混ぜるかを決める割合です。
例えば、男性の声を女性の声に変換する場合、Retrieval Feature Ratioを0.2にすると、男性的な声質が残りますが、0.8にすると、女性的な声質が強くなります。Retrieval Feature Ratioを調整することで、自分好みの音声変換ができるようになります。
設定し終わったら、inferを押す
inferを押したら、生成が開始されます。

生成の内容を確認し、音声をダウンロードします。